NVIDIA is gearing up to bring artificial intelligence to the 5G wireless edge starting next year. The company at the Mobile World Congress (MWC) event revealed its plans to make available network cards based on Arm processors that will have the compute power required to run AI inference engines on edge computing platforms. At the core of that effort is a NVIDIA Aerial software development kit (SDK) that NVIDIA is making available to developers.
The NVIDIA Aerial A100 AI-on-5G computing platform will be based on 16 Arm Cortex-A78 processors into the NVIDIA BlueField-3 A100 network card scheduled to become available in the first half of 2022. Those network cards are based on a data processing unit (DPU) that NVIDIA is bringing to market to offload network, storage, security, and now AI workloads from servers.
NVIDIA is in the middle of trying to acquire Arm as part of an effort that would create a behemoth large enough to counter Intel. In addition to running AI on graphical processor units (GPUs), NVIDIA is betting organizations will find it more cost efficient to offload AI inference engines on to Arm processors deployed in a variety of edge computing environments.
Also read: NVIDIA Extends Scope of AI Software Ambitions
AI on the Edge
Most AI models are trained in the cloud. However, when it comes time to deploy an application infused with AI an inference engine is required. The closer that inference engine runs to the point where data is being collected the better the overall application experience becomes, notes Gilad Shainer, vice president of marketing for NVIDIA. “This is where the DPU shines,” he said.
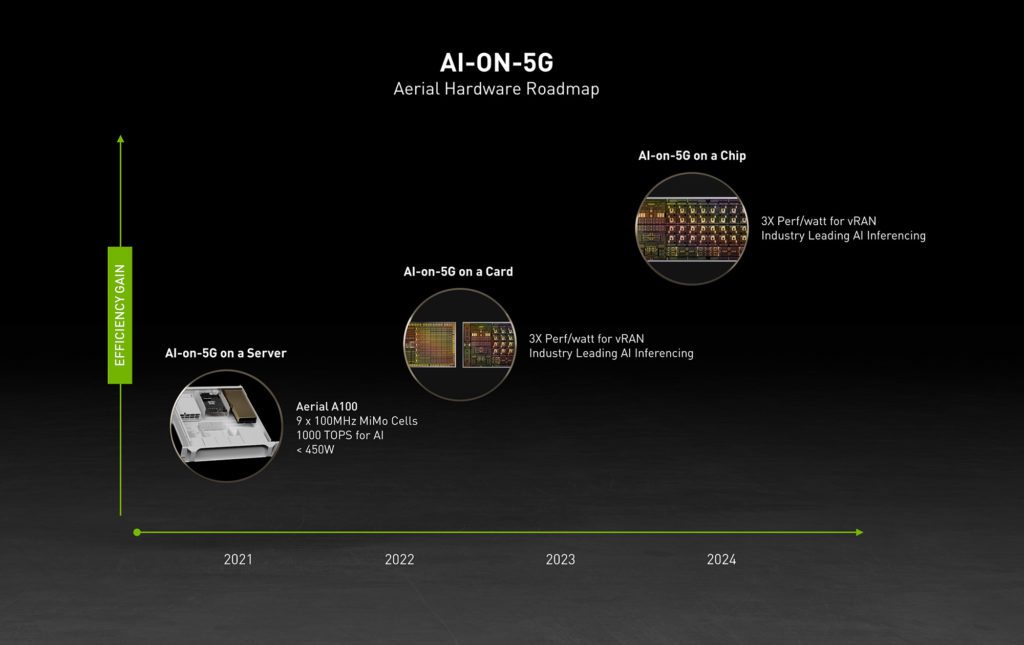
Offloading tasks from servers is hardly a new idea. NVIDIA is taking the concept a step further by weaving together graphics processor units (GPUs), traditional CPUs, and DPUs together under a common software architecture. Ultimately, the goal is to create a framework for training AI models using GPUs that then spawn inference engines optimized for processors that also happen to be from NVIDIA and its allies. In most cases, AI models are trained in cloud, but NVIDIA has also been making the case for certified GPU systems that can be deployed in on-premises IT environments.
Optimizing MLOps
One way or another the amount of compute horsepower available at the network edge for running AI models is about to substantially increase. The challenge now is optimizing best machine learning operations (MLOps) practices to reduce the friction that many organizations experience when building and deploying AI models today. In most cases, AI models are built by data scientists. Aligning their efforts with application development teams to make sure AI models are ready when applications need to be deployed has proven challenging. In fact, it’s not clear to what degree MLOps represents a truly separate IT discipline or is simply an aberration that will ultimately be folded into existing IT operations.
One way or another, however, AI is coming to the network edge. The next issue is deciding how best to deliver, manage, secure and update it once it gets there.
Read next: Open Source Platforms Vie with IT Vendors for Management of MLOps